



株式会社MIXIで
みてねでは機能の1つとして
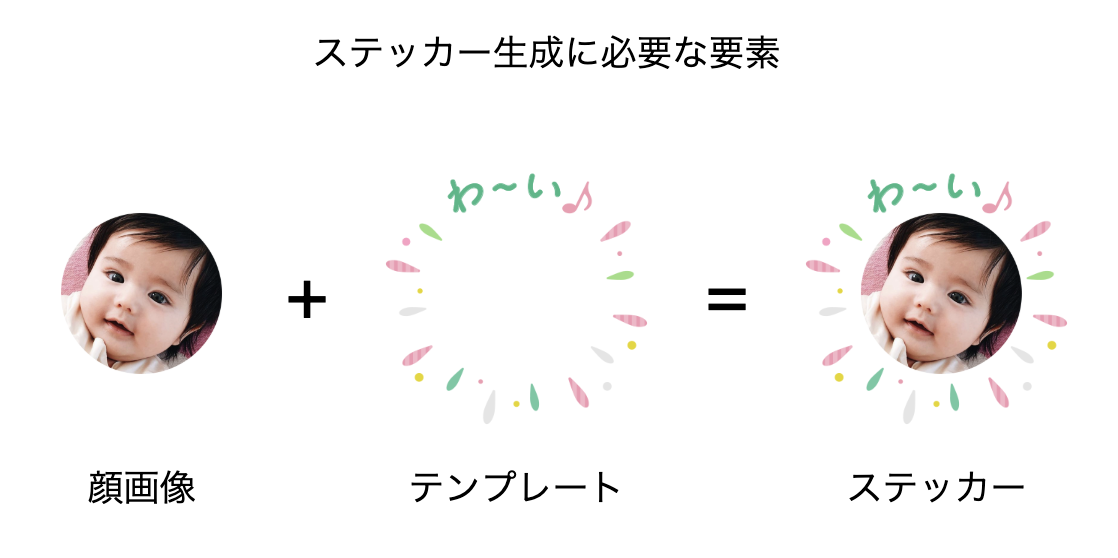
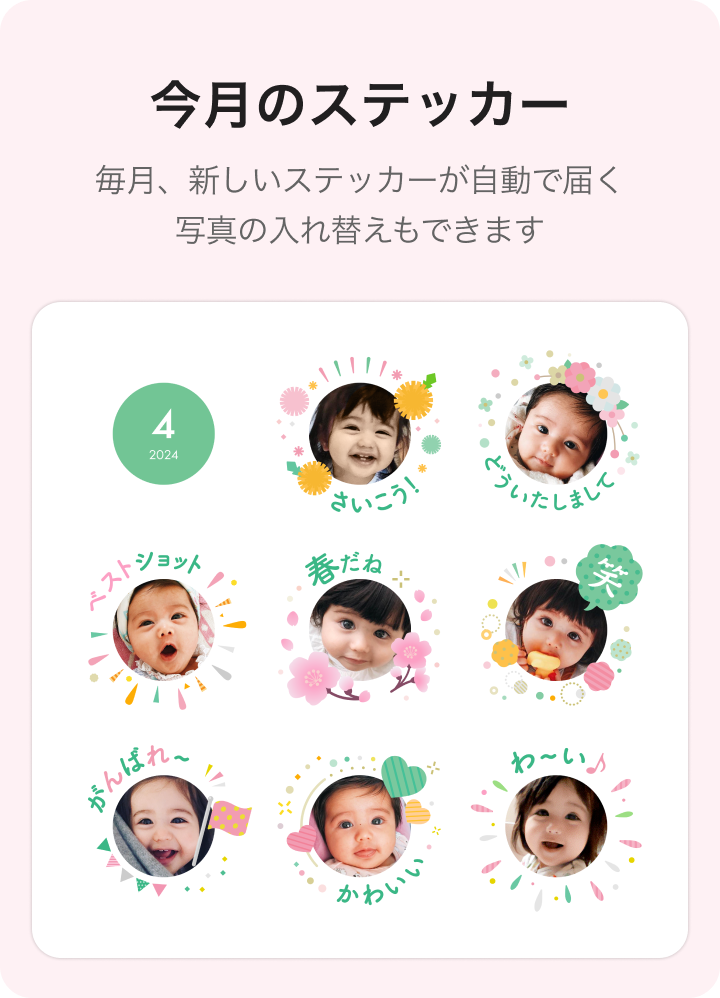
ステッカープランとは
みてねにアップロードされた画像から毎月8枚のステッカーを自動生成し配信するサービスです。配信されたステッカーはみてねアプリ内のコメント欄で使用でき、より気軽にコミュニケーションを取ることができます。また、ステッカーは毎月新しいデザインで作成されますので、配信されたステッカーを見るだけでも楽しんでいただけるプランとなっています。

ステッカー自動提案の処理の流れ
「ステッカー自動提案」
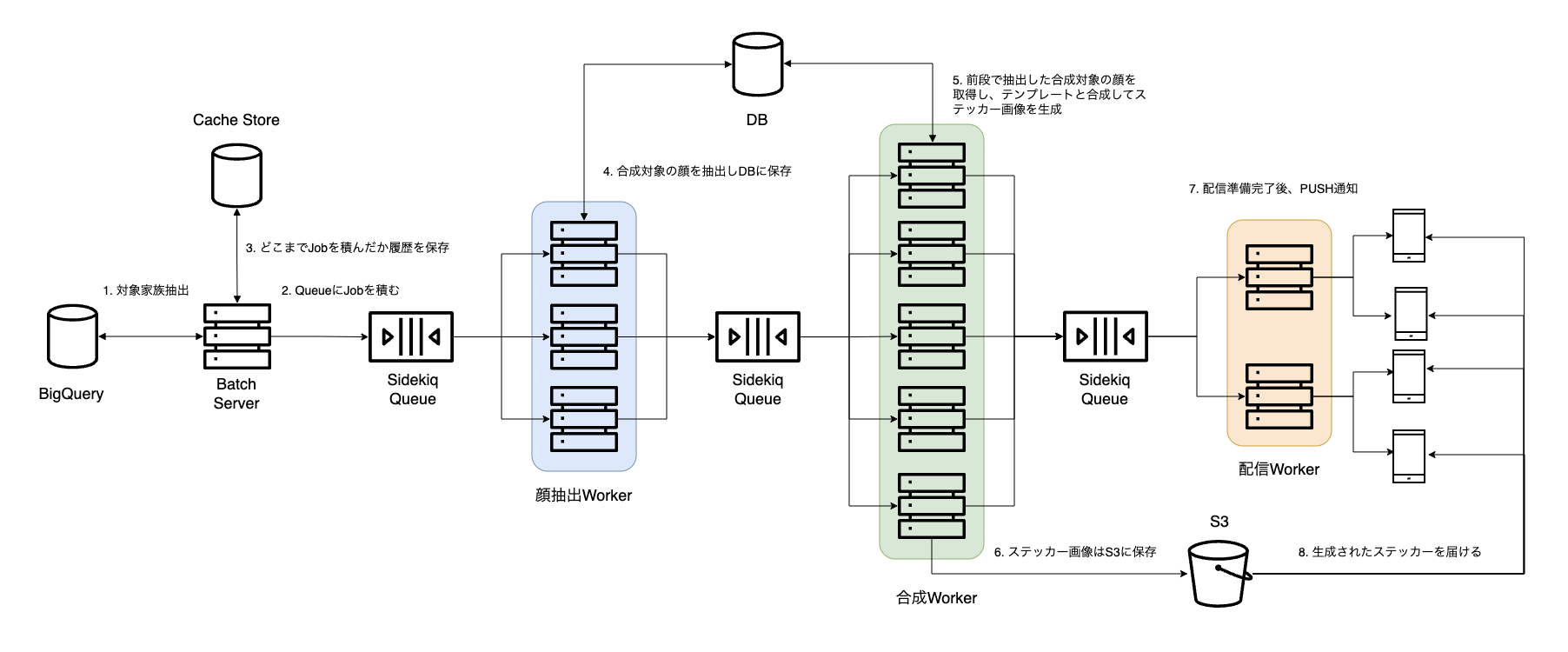
では、ステッカー自動提案をどのように実現しているのかを解説します。主にステッカー自動提案の処理は次の4ステップで構成されています。以降で各ステップの中身を詳細にみていきます。
- 自動提案を配信する家族を抽出
- 合成対象の顔を抽出
- 合成対象の顔とテンプレートを合成してステッカーを生成
- ステッカーを各家族に配信
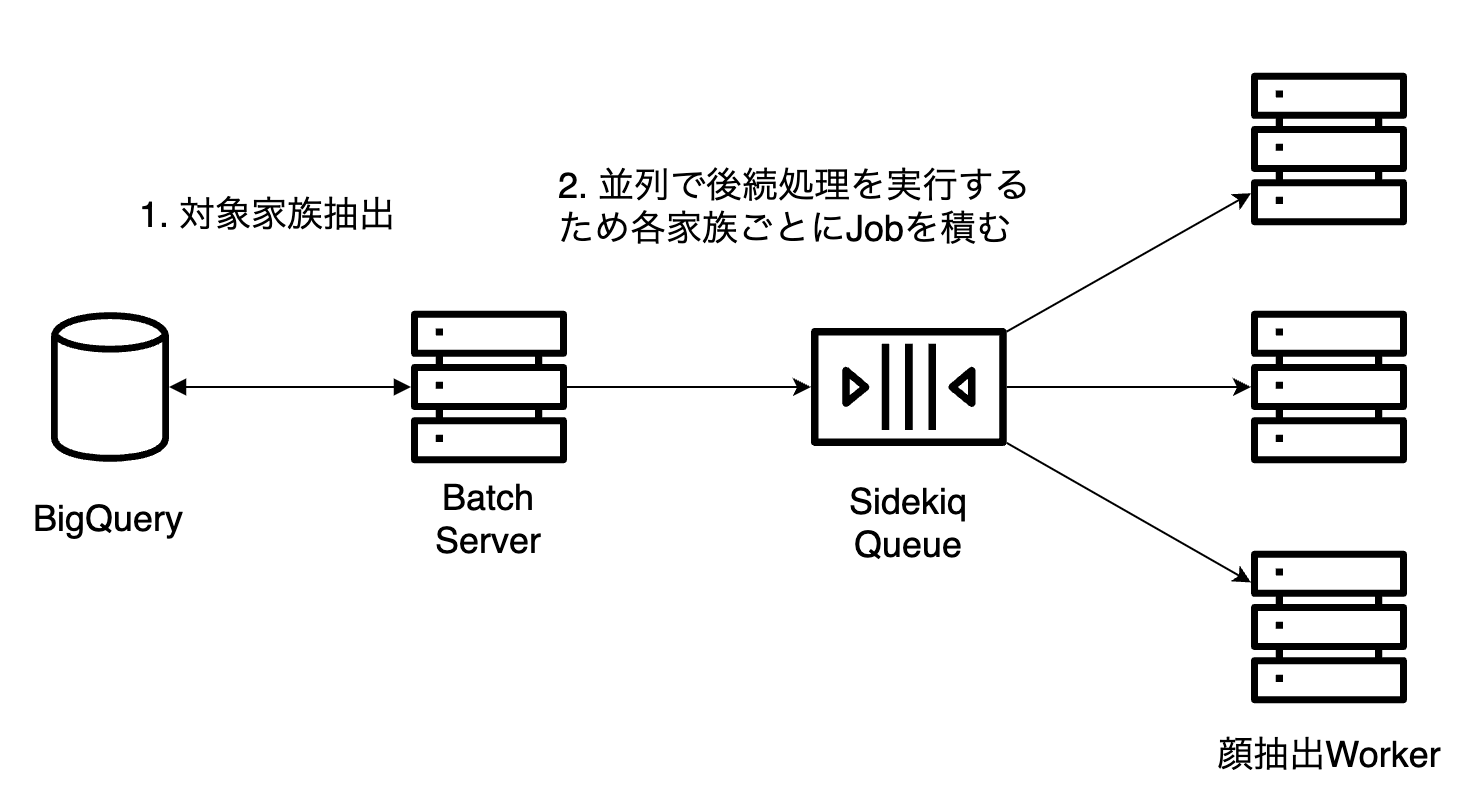
①自動提案を配信する家族を抽出
まず、ステッカー自動提案を配信する家族を抽出します。これは毎月任意のタイミングで定期バッチ
この配信対象の家族抽出処理は、Batch ServerからBigQueryへクエリを投げ取得しています。なぜなら、配信対象となる家族数は非常に多く、各家族のメディア数や直近のログイン履歴などから配信条件を満たすか否かの判定を行う必要があるため、アプリケーションデータベース
Batch Serverは配信対象家族を取得すると、並列で後続処理を実行するため各家族ごとにJobを作成し非同期ワーカー
しかし、Batch ServerはBigQueryから非常に多くの家族を取得するため途中で処理が停止した場合に、処理を最初から再実行するとJobを重複して積むので時間やコスト、DB負荷を余計にかけてしまいます。そのためBatch Serverには処理を途中から再開できる仕組み
- BigQueryから対象家族をユニークかつソート可能なキー
(仮称:family_ key) を参照し、特定の順序で取得する - Batch Serverはfamily_
keyを参考に特定の順序でJobをQueueに追加する - 「2」
で積んだJobに紐づくfamily_ keyをBatch Serverから参照可能な外部キャッシュストアに保存する (最後に積んだJobに紐づくfamily_ keyを更新し続ける) - 「2,3」
を 「1」 によって取得した対象家族のJobをすべて積むまで繰り返す

つまり、再実行でBigQueryへ対象家族抽出クエリを投げるときは、次のように条件を1つ付与することで未処理の対象家族のみを取得でき、処理を途中から再開できます。
# 通常の対象家族抽出クエリ
SELECT family_number FROM [table_name];
# 再実行時の対象家族抽出クエリ
SELECT family_number FROM [table_name] WHERE family_key > [外部キャッシュストアに保存されているfamily_key]
②合成対象の顔を抽出(顔抽出Worker)
合成対象の顔は、可能な限りお子さんの顔を選び、その中でもより良い顔を抽出することを目指しています。では、どのような処理で合成対象の顔が抽出されるのかを解説します。これは主に
a. アップロード時の画像・動画の解析処理
みてねでは、ユーザが画像・
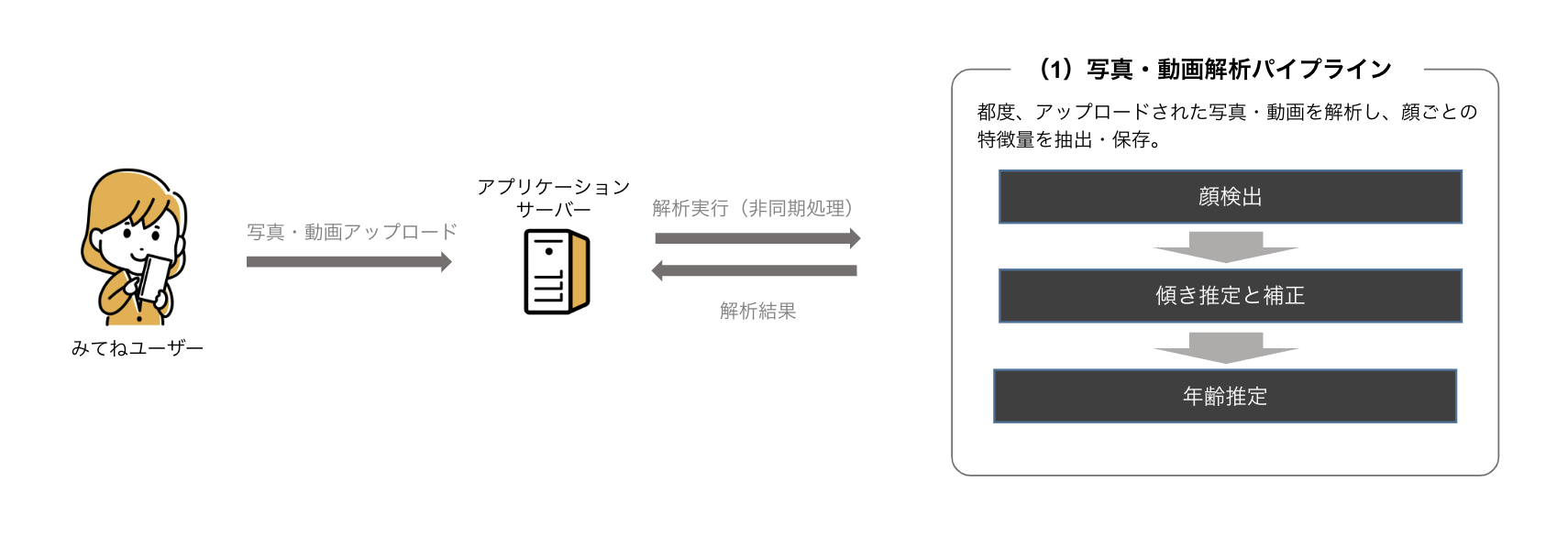
b. 画像フィルタ
顔を抽出する上で適していない画像を除外します。たとえば、事前の解析処理結果を参照し、顔が検出されていない画像や集合写真などの小さすぎる顔のみ検出される画像。また、
情報:Perceptual Hashとは、画像や動画などのメディアデータからハッシュ値を計算するアルゴリズムで、類似画像であればハミング距離は小さくなり
c. 顔フィルタ
画像から抽出した顔の中で適していない顔を除外します。たとえば、画像から見切れている顔、画像に対する顔面積が小さすぎる顔、横向き顔・
d. 顔スコアリング
顔フィルタを通過した顔の中でもより良い顔を抽出します。正面顔や画像に対する顔面積が大きめの顔、お気に入り・
③顔画像とテンプレートを合成(合成Worker)
前段で抽出した顔とテンプレートを合成してステッカー画像を生成します。
前段の顔抽出Workerと合成Workerを分割している理由は、パフォーマンスのボトルネックが異なるためです。顔抽出Workerは対象候補となる画像情報が保存されているレコードとそれに紐づく解析結果をDBから取得するため、Server⇔DB間のネットワーク通信の入出力操作がボトルネック
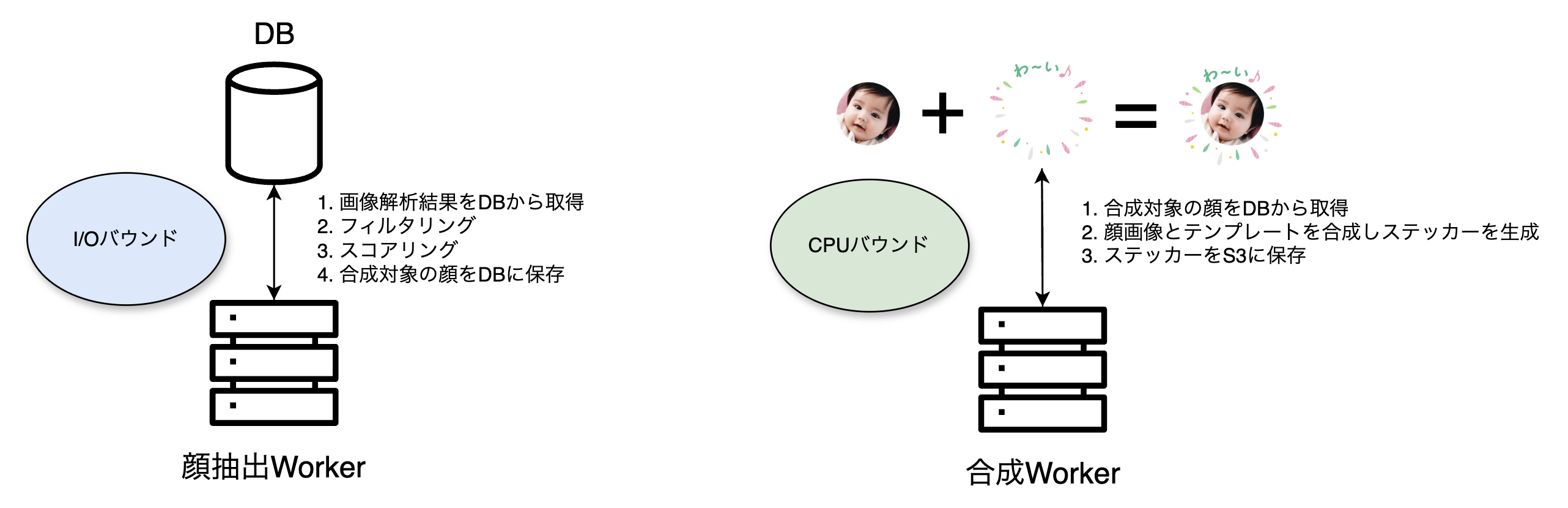
合成Workerは1家族につき複数枚のステッカー画像を生成するので処理時間も顔抽出Workerと比較すると長くなりますが、DBの負荷状態を考慮不要なため容易に並列数を上げることができます。また分割しておくことでMemory、CPUも各Workerに最適化した値に調整することができます。そして、遅延なく一連の処理を実行するため顔抽出Workerと合成Workerのスループットが同じになるよう並列数は自動スケーリングで調整しています。e.
④配信
生成されたステッカーは、iOS/
最後に
この記事では、ステッカープランの概要とみてねData Engineeringグループにおける取り組みのひとつとしてステッカー自動提案の仕組みやそれを支えるインフラ構成、BigQuery活用などの負荷対策についてご紹介しました。今後も負荷対策のほか、より最適な提案を行えるよう顔抽出ロジックなどの改善にも引き続き取り組んでいきます。