



ここ何年か、米国に行くたびにCerebras Systems社を訪問しています[1]。Cerebras は WSE - Wafer Scale Engine[2]と呼ばれる
コロナの影響で海外に行くことが難しくなったために、この夏、2年半の間を空けての再訪となりました。今回は新オフィスのようすなどをお届けします。
新オフィス
スタートアップは成長するにつれてオフィスを変えるのが常で、Cerebrasも前回訪問したオフィスから新しいところに引っ越していました。前回200人ほどだったスタッフも400人を超えたとのこと。

迎えてくれたのはAndy Hock氏。肩書きはVice President, Product Managementです。彼とも2年半ぶりの再会となりましたが、いつものように丁寧に対応してくれました。

新社屋はシリコンバレーの中心地、Sunnyvaleにあります。Andyによると、この地域は大規模なラボを必要とするようなハードウェア・
ラボ
新オフィスの魅力の1つはまさにそのラボです。以前のLos Altosのオフィスにもラボ・
ところで普通はスタートアップのラボに外部の者は入れません。デスクには開発途中のものがゴロゴロと転がっていますから当然です。気楽に写真を撮るわけにも行かず、ここにもあまり多くを掲載することができません。見たものすべて紹介したいところですが、そうもいかないことをご容赦ください。
ではラボ見学に参りましょう。


Rebecca
見学にはRebecca Lewington氏がガイドとして付いてくれました。Technology Evangelistの肩書きどおり、彼女はラボのあらゆることについて、つまりCerebrasで行われているすべての開発について、とても詳しく把握しています。

筆者はこういう開発現場に行くと、何を見ても
それにしてもCerebrasのラボは聞きたいことが無限に湧いてくるところでした。というのも、CerebrasはどうしてもWSE、つまりウェハーを1枚まるごと使った巨大チップに目が行きがちですが、彼らが作りだしたものはそれだけでないからです。
彼らはWSEという
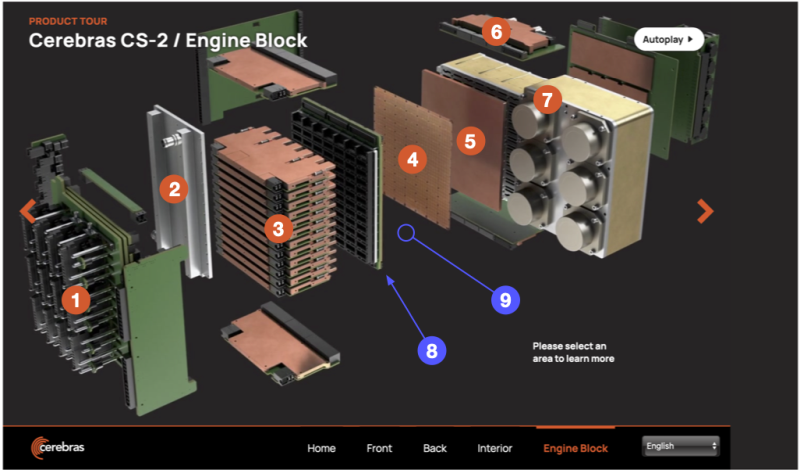
赤い丸が7つ付けられていますが、Webではそこをクリックすると各部の説明が出てきます。本稿では丸に番号を追加して、その順に各機能ブロックの名前を列挙しておきます。
①パワーディストリビューションモジュール
どれ1つとっても見るからに普通でない、つまり既製ではなく何らかの開発作業が必要なものばかりだと思えるでしょう。
そして赤丸が付いていないものにしても油断できません。たとえば③と④の間、青色の矢印⑧の先にあるソケットに覆われた電力供給用の基板を見て下さい。
しかし通常、プリント基板では電力は基板表面の銅箔を流れるもので、貫通する方向に流すものではありません。もちろんスルーホールは作れるでしょうが、従来的なスルーホールで穴だらけした基板に合計15KWもの電力を普通に流せるかどうか、筆者はパッと判断できません。
何をするにしても普通では済まず、彼らが基礎実験と試作を繰り返したであろうことがわかります。そんなわけで、そのあたりに置いてあるどのパーツにしても、それを手に取って眺めると

それと、

ちょっと写真ではわかりにくいですが、WSEと同じ形・
このコネクタについては2019年のHotChips 31での、Sean Lieによるプレゼン・
図の上側のSiliconがシステム構成図の④、下側のMain PCB Boardが同⑧です。その間にはさまっている
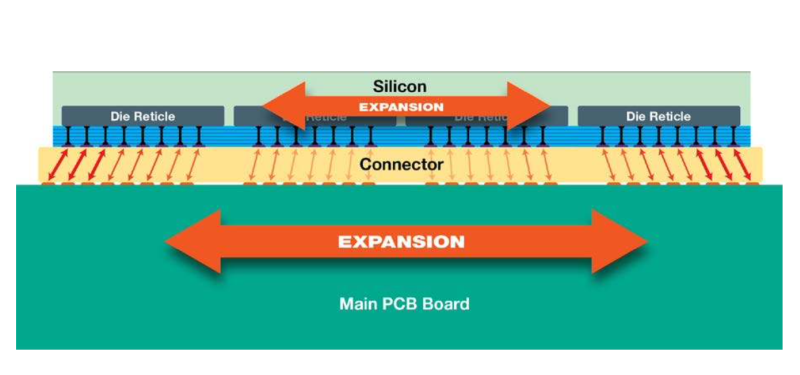
この図の下側の基板
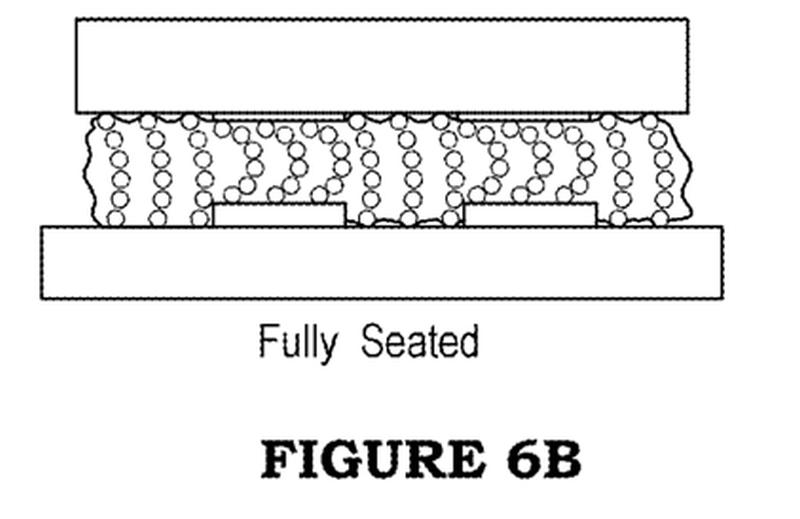
彼らはこのパーツの開発で特許を取っています[3]が、その特許本文ではElastomeric Connectorと呼ばれています。思ったより薄く、こんなに柔らかいものだったのかと驚きました。
このコネクタは下の図にあるように、押しつけるなどして変形したときにでも、中のボールの並びは柔軟に追随して接触を保つのです。実物がこんなに薄いものだとは思っておらず、ちょっと驚きました。
こういった過去のプレゼンや取材での議論などを通して聞いたものを直接、それもEvangelistであるRebeccaの解説を聞きながら手に取れたのは、とても良い経験となりました。
クリーンルーム
ラボ見学の最後にAndyはクリーンルームを

たしかに彼らの作業はシリコンダイを剥き出しで触る工程が多く、開発段階でクリーンルームが必要そうです。しかし以前のオフィスにはこうした設備はなかったはずで、これまではパートナーと一緒にやっていたとのことでした。もちろん今でもTSMCなどパートナーの設備でないと出来ないことも多いでしょうが、こうした設備を自前で運用することで彼らの開発サイクルがより加速されるのは間違いありません。
こんな大規模な、かつ全面的な開発が必要なプロジェクトを、始めてから4年半で最初の製品完成まで到達させた彼らの開発スピードには恐れ入るばかりなのですが、今後もこの超スピードで進んでいくのだろうなと感じました。
アップデート
ラボ見学のあと、Andyから最近のCerebrasの状況についてアップデートを受けました。

話題はいくつかあったのですが、本稿では2021年8月のHotChips 33で発表された、MemoryXとSwarmXを使った並列分散学習について取り上げることにします。
前回、筆者がCerebrasを訪問してから、いくつかのことが起きています。まず2世代目のマシン、CS-2が出ました。オリジナルのCS-1が40万コアという大規模データフローマシンだったところ、CS-2ではそのコア数が85万となりました。ただでさえ巨大な機械学習のモデルを分割することなくそのまま1台に吸い込めていたところが、さらに大きなモデルが扱えるようになったわけです。そして去年、複数のCS-2をクラスタとして扱う仕組みが発表されました。
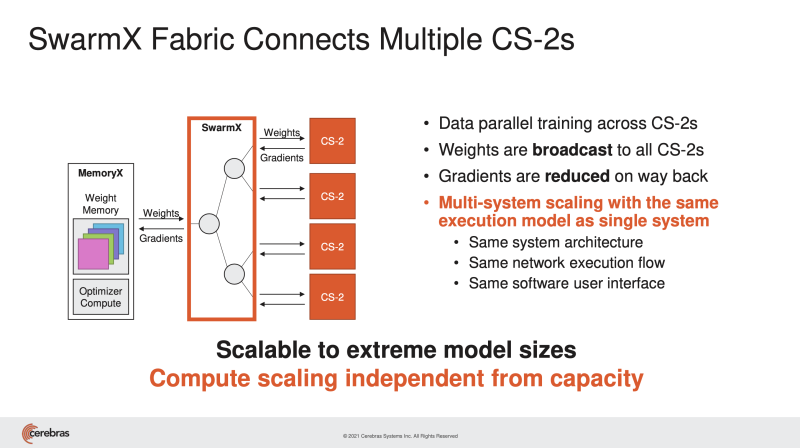
MemoryXはモデル全体のWeightを保持するもので、これをクラスタ内のすべてのCS-2にブロードキャストします。CS-2の中で得られた勾配
スライドで示された構成はデータ並列を指向しています。日々、先端的なAI応用に取り組んでいる人たちは
それに対してCerebrasは真逆の、つまりWSE1枚があまりにも巨大であるためにモデルを分割しないことを前提としたアプローチを取っていることが分かるでしょうか。
従来的なGPUを使ったシステムでは、モデルが1つのGPUに入り切らないためにパイプライン型のモデル並列処理が必要となるのです。1つのレイヤが大きすぎてGPUに収まらないから分割する必要が生じるのです。Andyによると
そしてAndyは分散学習のエンジニアリングコストの高さが問題だと指摘します。
-
Andy:GPT-3のような大規模なモデルを
(GPUを使った) クラスタシステムに分散させるには、さまざまな種類の並列化手法をすべて使用することになります。実際、アメリカや日本の有力なAI研究機関の話を聞いてきましたが、大規模なモデルを、たとえば数百・ 数千のGPUを持つクラスタに対して正しく分散配置する戦略を開発するだけでも、数カ月かかることがよくあります。これでは、開発が遅れ、技術革新が遅れ、AI研究者が本当の意味でAI研究をしていない状態になってしまいます。 そこで我々の出番です。つまりCS-2なら世界最大のモデルでさえ一台で動作可能で、もしもっと高速に処理したい場合はMemoryX/
SwarmXでデバイスをクラスタリングして、シンプルなデータ並列モードで実行すれば良いのです。それだけリニアにスケールアウトさせることができます。
本稿ではちゃんと説明しませんでしたが、もちろんこうしたデータ並列がうまく行えるのは、もともと各CS-2にあったWeight情報を外部化して共有するWeight Streamingの機構があるからです。この手法の詳細についてはHotChipsでの講演のサマリが動画に上がっていますので[4]、そちらをご覧ください。
原点
Andyは2018年から2020年の間に、最先端のAIモデルのパラメータが数億から数千億になった、つまり2年で3桁もの成長をしたことを示し、これに対応するためには根本的に異なる種類のコンピュート・
「ここで私がなぜCerebrasに入社したのか、その原点に立ち返ることになります」
-
Andy:私たちは、AI
(による応用) を加速するためにWafer Scale Engineを作りました。AIができることの可能性は広がるばかりです。AIコンピューティングの成長は、本当にまったく減速しません。最新の素晴らしい、そして大規模なモデルは、たとえばGoogle、Microsoft、Facebookなどで動いていますが、このような最新技術を扱う機会を持つ組織や人は、世界でもそれほど多くはありません。 私たちの願いは、こうしたモデルをより簡単に実行できるようにすること、より多くの組織や人々にその能力を提供し、誰もが最大のモデルを利用できるようにすることなのです。そうすることで、私たち全員がAIの可能性を現実にすることができるのです。
つまり彼らは、指数関数的なモデルの巨大化に対応し、AI応用の利益を多くの人たちが享受できるようにする、という大きな目標を持ちながら今も開発を続けているのです。
この彼らの大きなチャレンジが認められる出来事がありました。Mountain ViewにあるComputer History Museumが

Computer History MuseumはENIACやSAGE、IBM System 360、AltoそしてGoogleの最初のクラスタシステム
おわりに
スタートアップを取材していつも感じるのが、彼らはいつもそれぞれの大きなビジョンをもってプロジェクトに取り組んでいることです。そうしたビジョンを直接コアスタッフから聞くことができる、オフィスを訪問しての対面取材はやはり素晴らしいです。対応してくれたAndyとRebecca、そしてこの取材をアレンジしてくださった関係者の皆様に感謝します。